


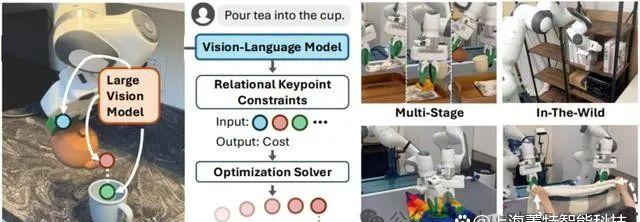
最近,着名人工智能科学家李飞飞团队发布了“空间智能”研究方向的最新突破,提出了关系关键点约束(ReKep,全称:RelationalKeypointConstraints)。
据了解,ReKep是一种基于视觉的表示方法,用于设定机器人操纵中的约束条件,从而优化其动作。它通过将环境中的三维关键点映射到数值本钱来定义这些约束,这些关键点具有任务语义和空间意义。
深度视觉与Franka机器人学习的深度融合倒茶、叠衣服、收拾整顿书籍、丢垃圾,现在的家务机器人干活真是越来越纯熟了。
他们把任务动作拆解后标记出几个关键点,再给到详细规则让机器人知道这些点之间有什么联系,要怎么操纵比较好。除此之外,机器人还能自主学习,越训练越厉害。
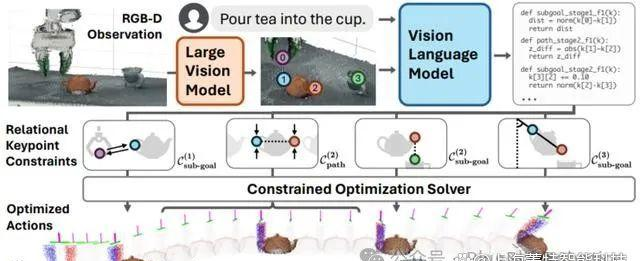
以倒茶这个动作为例,机器人会先用摄像头确定茶杯茶壶等的位置、外形等要素,再识别出关键点,好比茶杯的中心点和把手的中心点,ReKep会给机器人编写出一系列规则,告诉它要用什么角度、怎么拿怎么倾倒、用多大力气等,机器人只要按照规则步履就能成功倒茶了。


这些丝滑动作恰是进步Franka机器人力控技术+精妙框架设计+多模态大模型的加持。不得不说,这么一个简朴的动作想让机器人做好是真的是太难了。要是没有ReKep技术,想看到机器人熟练地干各种家务活还不知道要等到猴年马月。
究竟今年三月份的时候,李飞飞团队的家务机器人仍是这样的,只会擦擦桌子切个生果:而半年后的今天,就已经进化玉成能选手了:
目前,李飞飞团队关于ReKep技术的论文已在arXiv公然,代码也已开源。
论文标题:ReKep:Spatio-TemporalReasoningofRelationalKeypointConstraintsforRoboticManipulation论文地址:https://arxiv.org/pdf/2409.01652项目网站:https://rekep-robot.github.io/项目代码:github.com/huangwl18/ReKep李飞飞表示,该工作展示了视觉与机器人学习的更深层次融合!固然论文中没有提及李飞飞在今年5年初创立的专注空间智能的AI公司WorldLabs,但ReKep显然在空间智能方面大有潜力。
论文概述研究问题和念头李飞飞团队旨在解决与机器人操纵任务相关的挑战,这些任务涉及多个空间关系和时间依靠阶段,需要对复杂的空间和时间关系进行编码。
他们但愿开发一个广泛合用的框架,能够适应需要多阶段、野外环境、双手操纵和反应行为的任务,通过基础模型的进展在获取约束方面具有可扩展性,并能够实时优化以产生复杂的操纵行为。
难点与挑战现有的使用刚体变换表示操纵任务约束的方法缺乏几何细节,要求预定义的物体模型,并且无法处理可变形物体。
在视觉空间中直接学习约束的数据驱动方法也在收集练习数据时面临挑战,由于约束的数目在物体和任务方面呈组合增长。
技术创新李飞飞团队提出了一种名为关系关键点约束(ReKep)的方法,用于机器人操纵。
ReKep将操纵任务编码为约束,连接机器人与其环境,而无需手动标注。该方法利用Python函数将一组语义上有意义的三维关键点映射为数值本钱,从而能够表示复杂的空间和时间关系。
该框架旨在通过大型视觉模型和视觉-语言模型自动天生约束,实现从自然语言指令和RGB-D观测中高效地指定任务。
他们还提出了一种算法实例,可以实时高效地解决优化问题。
真实实验实验涉及多个任务,包括倒茶、回收罐、收拾整顿书籍、打包盒子、折叠衣物、装鞋盒和协作折叠等。这些任务被设计来测试系统在不同方面的机能,如空间和时间依赖性、对环境的适应性、双手协调和与人类的互动。

轮式单臂平台和固定式双臂平台的成功率
两个机器人平台在外部干扰下的成功率
ReKep用于折叠不同种别服装的新型双臂策略及其成功率实验结果显示,ReKep在多种任务上的成功率较高,证实了其在自动化操控任务中的潜力。成功率根据任务的不同而有所差异,但总体上表现良好。
技术解读关系关键点约束(ReKep)首先,他们定义了单个ReKep实例,并且假设已经指定了一组?个关键点。每个关键点??∈ℝ3指的是场景表面上的一个3D点,其坐标依赖于任务语义和环境(例如,手柄上的抓取点,壶嘴)。
本质上来说,一个ReKep实例编码了关键点之间的一个期望的空间关系,这些关系可能属于机器人手臂、物体部门或其他署理。
然而,一个操纵任务通常涉及多个空间关系,并且可能具有多个时间上依靠的阶段,每个阶段都涉及不同的空间关系。为此,他们将任务分解为?个阶段,并为每个阶段?∈{1,…,?}使用ReKep来指定两类约束:子目标约束路径约束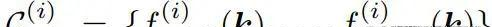
其中?sub-goal(?)编码阶段?结束时需要达到的关键点关系,而?path(?)编码阶段?内部需要满意的关键点关系。
如下图所示的倾倒任务由三个阶段组成:抓取、对齐和倾倒。
阶段1的子目标约束拉动末端执行器向茶壶手柄靠近。阶段2的子目标约束指定壶嘴需要位于杯口上方,阶段2的路径约束确保茶壶竖立,以避免倾倒时溢出。最后,阶段3的子目标约束指定倾倒角度。
操作任务作为ReKep约束优化问题他们将末端执行器姿态表示为e∈SE(3),将操控任务表述为一个优化问题,目标是找到一系列满意ReKep约束的末端执行器(end-effector)姿态,并将控制问题表述如下: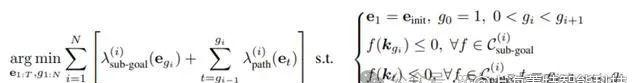
对于每个阶段,优化算法需要找到满意子目标约束的末端执行器姿态,以及实现这些子目标的路径。
分解与算法即时实例化为了实时求解优化问题,他们采用了分解方法,仅优化下一个子目标及其对应的路径。

子目标问题:首先解决子目标问题,确定当前阶段的末端执行器目标姿态。路径问题:在获得子目标姿态后,解决路径问题,规划从当前姿态到子目标姿态的轨迹。回溯:假如发现任何子目标约束不再满意,系统可以回溯到之前的阶段进行重新规划。关键点提议和ReKep天生为了使系统能够在给定自由形式任务指令的情况下执行野外任务,他们设计了一个使用大型视觉模型和视觉语言模型进行关键点提议和ReKep天生的管道,并分成了两个部门:关键点提议使用大型视觉模型(LVM),如DINOv2,来提取场景中的特征,并利用这些特征来识别潜伏的关键点。这些关键点通常是场景中具有语义意义的3D点,例如物体的边沿、角落或特定物体部门的中央。
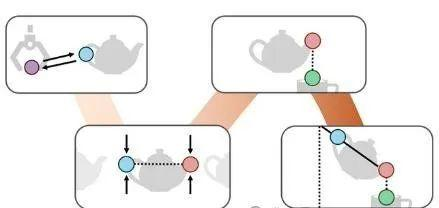
ReKep天生结合关键点和任务指令,使用视觉-语言模型(VLM)来天生ReKep,这些约束将用于指导机器人的动作规划和执行。这一步骤利用了视觉模型对场景的理解以及语言模型对指令的解释能力。
实验该团队通过实验对这套约束设计进行了验证,并尝试解答了以下三个问题:1.该框架自动构建和合成操纵行为的表现如何?
2.该系统泛化到新物体和操纵策略的效果如何?
3.各个组件可能如何导致系统故障?
使用ReKep操纵两台Franka机器臂他们通过一系列任务检查了该系统的多阶段(m)、野外/实用场景(w)、双手(b)和反应(r)行为。这些任务包括倒茶(m,w,r)、摆放书本(w)、回收罐子(w)、给盒子贴胶带(w,r)、叠衣服(b)、装鞋子(b)和协作折叠(b,r)。
分析系统错误该框架的设计是模块化的,因此很利便分析系统错误。该团队以人工方式检查了表1实验中碰到的故障案例,然后基于此计算了模块导致错误的可能性,同时考虑了它们在管道流程中的时间依靠关系。结果见图5。
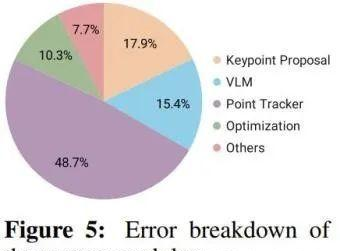
可以看到,在不同模块中,关键点跟踪器产生的错误最多,由于频繁和间或泛起的遮挡让系统很难进行正确跟踪。
来源:FRANKA
未经允许不得转载:头条资讯网_今日热点_娱乐才是你关心的时事 » 斯坦福大学AI科学家李飞飞携手Franka机器人创业“空间智能”方向









